Implementing and Optimizing Agentic Search
March 14th, 2026 by Lorre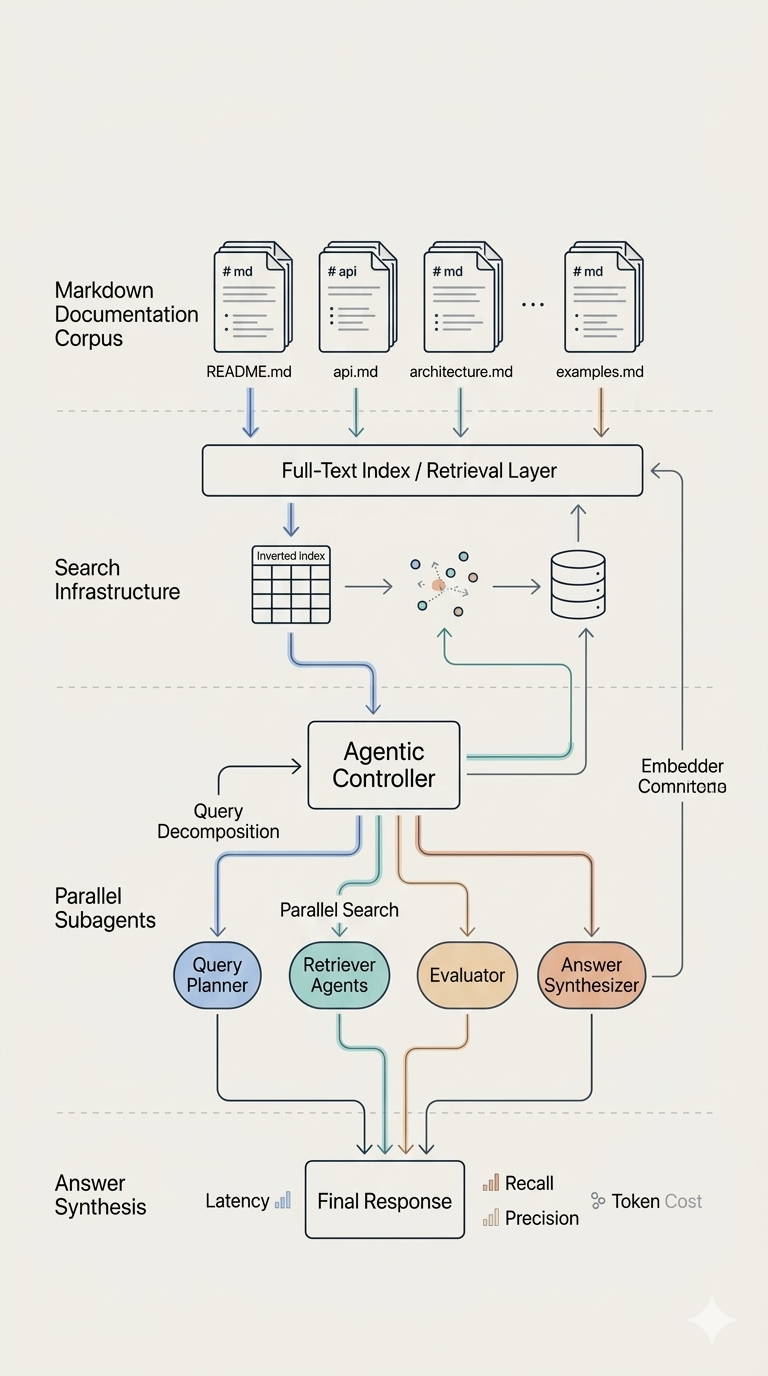
Abstract
This project explores four distinct approaches to agentic search over Markdown documentation corpora, ranging from filesystem-based agents to token-optimized parallel subagent architectures with full-text search indexing. Inspired by Benjamin Anderson’s Agentic Search for Dummies, this work implements and evaluates multiple RAG (Retrieval Augmented Generation) strategies, revealing critical tradeoffs between implementation complexity, retrieval accuracy, latency, and scalability.
All approaches utilize Anthropic Claude Sonnet 4.5 as the LLM engine and are evaluated against a curated test set drawn from LangChain’s DeepAgents and LangGraph documentation.
1. Introduction
Motivation
Retrieval Augmented Generation (RAG) has become the standard approach for grounding LLM responses in domain-specific knowledge. However, implementing production-quality agentic search requires navigating complex tradeoffs:
- Index vs. no-index: Should documents be pre-indexed for retrieval, or searched on-demand via filesystem tools?
- Direct tool access vs. subagent delegation: Should the main agent invoke search tools directly, or delegate to specialized subagents?
- Token efficiency: How can middleware overhead be minimized to stay within rate limits?
- Latency vs. recall: Does parallel search improve accuracy enough to justify increased response time?
This project systematically explores these questions through four implementations:
- DeepAgent with Virtual Filesystem - Index-free search using grep/glob tools
- DeepAgents CLI - Interactive sessions with filesystem-based discovery
- Tantivy LG Agent - LangGraph + BM25 full-text search (baseline)
- DeepAgent (2 subagent) + Tantivy - Parallel subagent delegation with token-optimized middleware
2. Corpus Selection and Preparation
Documentation Sources
The knowledge base consists of llm.txt-formatted documentation downloaded from LangChain’s Python SDK documentation sites:
- DeepAgents docs: 12 Markdown files covering agent architecture, middleware, tools, and skills
- LangGraph docs: 29 Markdown files on state graphs, persistence, and human-in-the-loop workflows
These documents were chosen for several reasons:
- Well-structured content: Clear hierarchical organization with consistent formatting
- Knowledge gaps in LLMs: Recent framework updates not fully represented in Claude’s training cutoff
- Minimal preprocessing: No need for complex multi-modal parsing (PDFs, HTML, images)
- Domain familiarity: Sufficient background knowledge to evaluate response quality manually
Augmented Index Generation
For metadata-enriched retrieval, an augmented JSONL index was generated using Google Gemini with the following prompt template:
Given text from {document_name}, provide the following metadata as JSON:
- `filename` str: {document_name}
- `keywords` list[str]: Keywords/keyphrases that someone might search for
where this section would be relevant. Can include semantic matches, synonyms,
and related concepts (not just literal text matches).
- `description` str: A SHORT summary of what the section says. Avoid making
overlong summaries; the goal is a quick overview, not a verbose paraphrase.
[document_name]: <>
[text]: <>
Provide JSON response only, no commentary.
This process was manual and time-consuming (>10 files), revealing a need for automation. A future enhancement would use an agentic workflow to loop over corpus directories and generate complete augmented indices programmatically.
3. Architecture Overview
All four approaches share a common goal - answer user queries with cited passages from the documentation - but differ fundamentally in their retrieval and orchestration strategies.
Approach 1: DeepAgent with Virtual Filesystem
User Query
|
v
+-------------------------+
| create_deep_agent() |
| - StateBackend (VFS) |
| - Filtered tools |
| - MemorySaver |
+-------------------------+
|
v
+-------------------------+
| Virtual Filesystem |
| /docs/deepagents/*.md |
| /docs/langgraph/*.md |
+-------------------------+
|
v
grep/glob/read_file
|
v
Claude Sonnet 4.5 -> Answer with Citations
Key characteristics:
- No index building; documents loaded into virtual filesystem via
StateBackend - Read-only access (write/edit tools filtered out)
- Uses filesystem tools (
ls,grep,glob,read_file) for retrieval - Multi-turn conversation memory via
MemorySaver
Tradeoffs:
- Zero index maintenance
- Dynamic corpus updates (files added on-the-fly)
- Inefficient token usage (loads full documents into context)
- No ranked retrieval (relies on sequential grep/glob)
- Context poisoning risk with many files
Approach 2: DeepAgents CLI (Not evaluated)
deepagents CLI (Interactive REPL)
|
v
.deepagents/
|- AGENTS.md (project context)
|- skills/doc-search/
|
v
File System Tools (ls/grep/glob/read)
|
v
Claude Sonnet 4.5 -> Answer with Citations
Key characteristics:
- Interactive REPL with built-in multi-turn conversation
- Session persistence via SQLite (
sessions.db) in.deepagents/ - Human-in-the-loop safety controls for tool execution
- Project-specific skills auto-loaded from
.deepagents/skills/
Tradeoffs:
- Out-of-the-box interactive experience
- Session management (resume conversations across restarts)
- Great for exploratory workflows
- Same token inefficiency as Approach 1
- No ranked retrieval
Approach 3: Tantivy LangGraph Agent (Baseline)
User Query
|
v
LangGraph StateGraph
|
|--> search_docs(queries) --> Tantivy Index (BM25 + RRF)
| | |
| +--------- Previews --------+
|
|--> read_docs(doc_ids) --> Full Content Retrieval
| |
| +--------- Full Text -------+
| |
+--> Claude Sonnet 4.5 -----------+
|
v
Answer with Numbered Citations
Key characteristics:
- Direct LangGraph workflow (
StateGraph+ToolNode) - BM25 full-text search with Reciprocal Rank Fusion (RRF) for multi-query retrieval
- Two-phase search pattern:
search_docs(): Returns ranked previews (doc_id, filename, description, score)read_docs(): Fetches full content for selected document IDs
- Conversation memory via
MemorySavercheckpointer - Automatic index building/updating via
IndexManager
Tradeoffs:
- Ranked retrieval (BM25) with query fusion (RRF)
- Two-phase search prevents context bloat
- Scalable to large corpora
- Requires index maintenance
- Single-agent sequential tool execution (no parallelism)
Approach 4: DeepAgent (2 subagent) + Tantivy
User Query
|
v
Parent Agent (create_agent + minimal middleware)
|
|--> Formulates 2 query variations
|
|--> Delegates BOTH IN PARALLEL via task tool
| |
| |--> search_subagent #1
| | |--> search_docs(queries) --> Tantivy (BM25+RRF)
| | +--> read_docs(doc_ids) --> Full Content
| |
| |--> search_subagent #2
| | |--> search_docs(queries) --> Tantivy (BM25+RRF)
| | +--> read_docs(doc_ids) --> Full Content
| |
| +--> Returns findings from both subagents
|
+--> Consolidates results -> Claude Sonnet 4.5
|
v
Answer with Numbered Citations
Key characteristics:
- Parallel subagent delegation: Parent agent spawns 2 concurrent search subagents
- Each subagent formulates queries, searches Tantivy index, and reads documents independently
- Token-optimized middleware stack: Uses
create_agentinstead ofcreate_deep_agentfor precise control - Same BM25 + RRF + two-phase search as Approach 3
Tradeoffs:
- Parallel retrieval (2 concurrent searches)
- Token-optimized (~12k tokens/query vs ~46k)
- Better recall potential (dual query variations)
- Increased latency due to orchestration overhead
- Higher implementation complexity
4. Token Optimization: From 46,000 to 12,000 Tokens
The Rate Limit Problem
Initial implementation of Approach 4 using create_deep_agent triggered Anthropic Claude Sonnet 4.5 rate limit errors (30,000 input tokens/min) when 3 sub-agents were designated. Per-query token consumption was ~46,000 tokens, exceeding the limit when multiple queries were issued in quick succession.
Root Cause Analysis
create_deep_agent (from the DeepAgents library) hardcodes a default middleware stack that includes:
- TodoListMiddleware (~1,182 tokens/call) - Planning capabilities
- FilesystemMiddleware (~841 tokens/call) - File system access
- MemoryMiddleware (~1,116 tokens/call) - Loads context from AGENTS.md
- SubAgentMiddleware with default
task_description(6,914 characters) - Subagent delegation
For a search-only workflow, TodoList, Filesystem, and Memory middleware are unnecessary overhead.
Optimization Strategy
The solution was to replace create_deep_agent with create_agent (from LangChain) and manually construct a minimal middleware stack:
# Before: create_deep_agent (46,000 tokens/query)
agent = create_deep_agent(
model=llm,
tools=[search_docs, read_docs],
...
)
# After: create_agent with manual middleware (12,000 tokens/query)
agent = create_agent(
model=llm,
tools=[search_docs, read_docs],
state_modifier=system_prompt,
checkpointer=checkpointer,
default_middleware=[
SubAgentMiddleware(
task_description=CUSTOM_TASK_DESCRIPTION, # 400 chars vs 6,914
system_prompt=SEARCH_SYSTEM_PROMPT,
default_middleware=[], # No middleware on subagents
),
SummarizationMiddleware(),
AnthropicPromptCachingMiddleware(),
PatchToolCallsMiddleware(),
],
)
Token Savings Breakdown
| Optimization | Token Savings |
|---|---|
| Removed TodoListMiddleware | ~1,182 tokens/call |
| Removed FilesystemMiddleware | ~841 tokens/call |
| Removed MemoryMiddleware | ~1,116 tokens/call |
Custom task_description (~400 chars vs 6,914 default) |
~1,500 tokens/call |
default_middleware=[] on subagents |
~2,000 tokens/subagent call |
| Reduced from 3 to 2 parallel queries | ~4,400 tokens/query |
Total reduction: 46,000 -> 12,000 tokens per query (74% reduction)
Why create_agent Instead of create_deep_agent?
create_deep_agent does not expose:
task_descriptionparameter (for SubAgentMiddleware)default_middlewarecontrol (for subagents)system_promptoverride (for subagent instructions)
These parameters are only accessible via create_agent, which provides full control over the middleware stack.
5. Parallel Query Delegation Architecture
System Prompt Modification
The parent agent’s system prompt was modified to explicitly instruct parallel subagent delegation:
You are a search coordinator agent. When the user asks a question:
1. Formulate TWO distinct query variations:
- Query 1: Direct keywords/phrases from the user's question
- Query 2: Synonyms, related concepts, or semantic variations
2. Delegate BOTH queries IN PARALLEL using the task tool:
- Spawn 2 subagents concurrently (do NOT wait for one to finish before starting the other)
- Each subagent will search independently and return findings
3. Consolidate results from both subagents and provide a unified answer with numbered citations.
Custom Task Description
The task_description parameter (shown to the LLM when it uses the task tool) was reduced from 6,914 characters to ~400 characters:
CUSTOM_TASK_DESCRIPTION = """
Delegate this search query to a specialized subagent.
The subagent will use search_docs and read_docs to find relevant documentation.
Return the subagent's findings.
"""
This concise description eliminates verbose documentation about filesystem tools, memory management, and other irrelevant middleware features.
6. Evaluation Methodology
Test Set Design
A test set of 5 questions was manually created based on the DeepAgents documentation corpus:
| Question | Difficulty | Expected Source Files |
|---|---|---|
| Q1: What are subagents and when should you NOT use them? | Easy | deepagents-subagents.md |
| Q2: How do you configure long-term memory? | Medium | deepagents-long-term-memory.md, deepagents-backends.md |
| Q3: What types of decisions can HITL handle? | Easy | deepagents-human-in-the-loop.md |
| Q4: What’s the difference between skills and tools? | Medium | deepagents-skills.md, deepagents-overview.md |
| Q5: How would you build a research agent with memory? | Hard (multi-hop) | deepagents-subagents.md, deepagents-long-term-memory.md |
Evaluation Metrics
- Hit Rate: Percentage of expected reference documents successfully retrieved
- Latency: Time from query submission to final answer
- Files Consulted: Number of documents read during retrieval
- Response Quality: Manual assessment of answer correctness and citation accuracy (graded /10)
Caveats
This evaluation is scaffolding-level and should be interpreted cautiously:
- Small test set (n=5)
- Corpus size is modest (12 files)
- Questions lack diversity in reasoning patterns (few adversarial/”gotcha” queries)
A production evaluation would require:
- Larger test set (n=50+)
- Multi-hop reasoning chains
- Adversarial questions about topics not in the corpus
- Automated evaluation via LLM-as-judge framework
7. Results and Analysis
Summary Results
| Metric | Approach 1 (DeepAgent) | Approach 3 (Tantivy LG) | Approach 4 (Tantivy Subagents) |
|---|---|---|---|
| Avg Time | 32.7s | 34.6s | 79.3s |
| Avg Hit Rate | 100% | 100% | 90% |
| Files per Query | 7-12 | 1-5 | 2-4 |
| Response Quality | 10/10 | 10/10 | 9/10 |
Approach 3 (Baseline): Direct Tool, No Subagent
| Question | Difficulty | Time | Hit Rate | Files Consulted |
|---|---|---|---|---|
| Q1: Subagents purpose/when NOT to use | Easy | 20.8s | 100% | deepagents-subagents.md, deepagents-overview.md |
| Q2: Long-term memory configuration | Medium | 29.6s | 100% | deepagents-long-term-memory.md, deepagents-backends.md, deepagents-harness.md, deepagents-overview.md |
| Q3: HITL decision types | Easy | 18.1s | 100% | deepagents-human-in-the-loop.md |
| Q4: Skills vs tools difference | Medium | 27.6s | 100% | deepagents-skills.md, deepagents-overview.md, deepagents-quickstart.md, deepagents-customization.md |
| Q5: Research agent (multi-hop) | Hard | 76.7s | 100% | deepagents-subagents.md, deepagents-long-term-memory.md + 3 others |
| Average | 34.6s | 100% |
Approach 4 (Subagent Delegation): Parallel Query Architecture
| Question | Difficulty | Time | Hit Rate | Files Consulted |
|---|---|---|---|---|
| Q1: Subagents purpose/when NOT to use | Easy | 39.9s | 100% | deepagents-subagents.md, deepagents-middleware.md, deepagents-harness.md, deepagents-overview.md |
| Q2: Long-term memory configuration | Medium | 92.1s | 50% | deepagents-long-term-memory.md, deepagents-harness.md, deepagents-overview.md |
| Q3: HITL decision types | Easy | 82.0s | 100% | deepagents-human-in-the-loop.md, deepagents-cli.md |
| Q4: Skills vs tools difference | Medium | 76.2s | 100% | deepagents-skills.md, deepagents-cli.md, deepagents-quickstart.md, deepagents-customization.md |
| Q5: Research agent (multi-hop) | Hard | 106.2s | 100% | deepagents-subagents.md, deepagents-long-term-memory.md |
| Average | 79.3s | 90% |
Key Findings
1. Approach 3 (Baseline) is More Efficient
Latency: Approach 3 is 2.3x faster on average (34.6s vs 79.3s)
- Direct tool invocation avoids orchestration overhead
- No need to formulate query variations or consolidate subagent results
- Fewer LLM round-trips (1-2 vs 3+)
Retrieval Precision: Approach 3 reads 1-5 files vs 2-4 files for Approach 4
- BM25 ranking naturally prioritizes the most relevant documents
- Subagent delegation introduces redundancy (both subagents may retrieve overlapping results)
2. Parallel Subagents Add Orchestration Cost
The subagent architecture incurs overhead at multiple levels:
- Planning phase: Parent agent formulates 2 query variations
- Delegation phase: Parent dispatches tasks via
tasktool calls - Execution phase: Both subagents run in parallel (good!)
- Consolidation phase: Parent synthesizes results from both subagents
This results in a minimum of 3 serial LLM round-trips (planning -> execution -> consolidation), whereas Approach 3 requires only 1-2 round-trips (search -> read -> answer).
3. Hit Rate Degradation on Q2
Q2 (long-term memory configuration) requires content from:
deepagents-long-term-memory.md(configuration examples)deepagents-backends.md(backend interface details)
Approach 4 missed deepagents-backends.md, achieving only 50% hit rate.
Root cause: The 2 parallel query variations did not produce sufficiently different keyword coverage. Both subagents likely formulated similar queries (e.g., “long-term memory configuration”, “memory persistence”), which retrieved the same top-ranked document.
Mitigation strategies:
- Increase number of parallel queries from 2 to 3-4 (trades off token usage)
- Implement query diversity constraints in system prompt (e.g., “Query 2 must use synonyms not present in Query 1”)
- Hybrid retrieval: Combine BM25 with semantic search for better coverage
4. Response Quality Remains High
Both approaches produced correct, well-cited answers for all questions. The 9/10 score for Approach 4 reflects the missing reference file in Q2, not a factual error in the response.
8. Deep Learnings from DeepAgents
Middleware Architecture
DeepAgents enables three built-in middleware components by default:
- TodoListMiddleware - Provides planning capabilities via
write_todostool - FilesystemMiddleware - Provides file operations (
ls,read_file,write_file,edit_file,glob,grep) - SubAgentMiddleware - Provides the
tasktool for delegating to subagents
These middleware layers inject tools and system prompt additions into the agent’s execution context. For specialized workflows (e.g., search-only), removing unnecessary middleware is critical for token efficiency.
Built-in Tools
DeepAgents exposes the following tools:
| Tool | Purpose | Middleware |
|---|---|---|
write_todos |
Manage task list | TodoListMiddleware |
ls, read_file, write_file, edit_file |
File operations | FilesystemMiddleware |
glob, grep |
File search | FilesystemMiddleware |
execute |
Run shell commands | SandboxBackendProtocol |
task |
Delegate to subagents | SubAgentMiddleware |
SDK vs CLI Differences
DeepAgents SDK:
- Requires manual conversation memory setup (
MemorySaver+ checkpointer) - Full control over middleware stack (via
create_agent) - LangSmith tracing enabled by setting
LANGSMITH_API_KEY
DeepAgents CLI:
- Multi-turn conversations enabled by default
- Session persistence via SQLite (
sessions.dbin.deepagents/) - Human-in-the-loop safety controls (user approves tool execution)
- Project skills auto-loaded from
.deepagents/skills/
Trace Viewer for CLI Sessions
The DeepAgents CLI stores session metadata in .deepagents/sessions.db (SQLite). A custom trace_viewer.py script was written to audit and visualize past sessions:
uv run scripts/trace_viewer.py --session abc123
This could be extended to:
- Aggregate token usage across sessions
- Visualize conversation flow graphs
- Export sessions for evaluation datasets
9. Comparison of Approaches
| Feature | Approach 1 (DeepAgent) | Approach 2 (CLI) | Approach 3 (Tantivy LG) | Approach 4 (Tantivy Subagents) |
|---|---|---|---|---|
| Technology | DeepAgents + Virtual FS | DeepAgents CLI | LangGraph + Tantivy | DeepAgents + Tantivy |
| Index Required | No | No | Yes | Yes |
| Retrieval Method | grep/glob (unranked) | grep/glob (unranked) | BM25 + RRF (ranked) | BM25 + RRF (ranked) |
| Parallel Search | No | No | No | Yes (2 subagents) |
| Token Efficiency | Poor (full docs loaded) | Poor (full docs loaded) | Good (two-phase search) | Excellent (minimal middleware) |
| Latency | 32.7s (avg) | N/A | 34.6s (avg) | 79.3s (avg) |
| Hit Rate | 100% | N/A | 100% | 90% |
| Setup Complexity | Low | Low | Medium | High |
| Best For | Small, dynamic corpora | Interactive exploration | Production baseline | Complex queries with high recall needs |
Recommendations
Use Approach 1 (DeepAgent FS) when:
- Corpus is small (<20 files)
- Documents change frequently (no index maintenance desired)
- Quick prototyping is the goal
Use Approach 2 (CLI) when:
- Interactive exploration is primary workflow
- Session persistence is valuable (resume conversations)
- Human-in-the-loop safety is required
Use Approach 3 (Tantivy LG) when:
- Corpus is large (100+ files)
- Retrieval accuracy is paramount (BM25 ranking)
- Latency must be minimized
Use Approach 4 (Tantivy Subagents) when:
- Recall is more important than latency
- Multi-hop queries are common
- Token optimization is necessary for rate limit compliance
10. Future Work
1. Semantic Search Baseline
Implement a naive chunking + embedding strategy for comparison:
- Chunk documents into 512-token segments
- Embed chunks using OpenAI
text-embedding-3-large - Store in vector database (e.g., Pinecone, Weaviate)
- Retrieve top-k chunks via cosine similarity
Hypothesis: For well-structured documentation (like this corpus), semantic search may perform comparably to agentic search with lower latency.
Required setup:
- Vector database deployment
- Embedding pipeline for new documents
- User query embedding at retrieval time
2. Hybrid Search (BM25 + Semantic)
Combine lexical (BM25) and semantic (embeddings) retrieval using RRF fusion:
# Retrieve top-k from BM25
bm25_results = tantivy_search(query)
# Retrieve top-k from vector search
vector_results = vector_db.search(embed(query))
# Fuse using RRF
final_results = rrf_fusion(bm25_results, vector_results, k=60)
This captures both exact keyword matches (BM25) and semantic similarity (embeddings).
3. Larger Corpus and Evaluation Suite
Extend to 100+ files and 50+ test questions with:
- Multi-hop reasoning: “How do you build a research agent that uses memory and spawns subagents?”
- Adversarial questions: “What is the default timeout for API calls?” (not in corpus)
- Ambiguous queries: “How do I configure memory?” (could refer to conversation memory, long-term memory, or context quarantine)
4. Automated Augmented Index Generation
Replace the manual Gemini workflow with a LangGraph pipeline:
# Pseudocode
for file in corpus_dir.glob("*.md"):
chunks = chunk_document(file)
for chunk in chunks:
metadata = llm_generate_metadata(chunk, prompt_template)
index.append(metadata)
index.save("augmented_index.jsonl")
5. Document Chunking for Approach 4
Reduce input tokens by chunking source documents:
- Current:
read_docs()returns full document content - Proposed:
read_docs()returns relevant chunks only
Implementation:
- Store document chunks in Tantivy index (not full documents)
search_docs()ranks chunks, not filesread_docs()retrieves specific chunk IDs
Expected benefits:
- Reduced context size (3-5 chunks vs 1-2 full documents)
- Faster LLM processing
- Lower risk of context poisoning
6. Context Compaction Techniques
Apply prompt compression methods to reduce input tokens:
- Provence: Prunes irrelevant sentences from retrieved documents
- LLMLingua-2: Compresses prompts by removing filler words while preserving semantics
Target: Reduce per-query tokens from 12,000 to <8,000 to fit 3-4 queries within the 30k tokens/min rate limit.
11. Conclusion
This project demonstrates that agentic search is not a one-size-fits-all solution. The optimal approach depends on corpus size, retrieval accuracy requirements, latency constraints, and token budgets.
Key takeaways:
- Index-free approaches (Approaches 1 & 2) are viable for small, dynamic corpora but suffer from poor token efficiency and lack of ranked retrieval.
- BM25-based RAG (Approach 3) provides an excellent baseline with fast retrieval, high hit rates, and manageable complexity.
- Parallel subagent delegation (Approach 4) improves recall potential but introduces significant latency overhead. It is most valuable for complex, multi-hop queries where exhaustive search is critical.
- Token optimization is non-negotiable for production workflows. Stripping unnecessary middleware reduced token consumption by 74% (46k -> 12k), preventing rate limit errors.
- Two-phase search (preview -> read) is essential for preventing context bloat and maintaining retrieval precision.
Future work will explore hybrid search (BM25 + embeddings), larger evaluation sets, and automated index generation to scale these approaches to production-grade RAG systems.
References
- Anderson, B. (2024). Agentic Search for Dummies. https://benanderson.work/blog/agentic-search-for-dummies/
- LangChain DeepAgents Documentation: https://docs.langchain.com/oss/python/deepagents/overview
- Tantivy-py: https://github.com/quickwit-oss/tantivy-py
Repository: https://github.com/latlan1/agentic_search
Test Results: See tests/ directory for full evaluation suite
